{{
}}
Citizen science for plant identification: insights from Pl@ntnet
Joseph Salmon
IMAG, Univ Montpellier, CNRS, Montpellier
Institut Universitaire de France (IUF)
![]()

![]()
![]()
Mainly joint work with:
- Tanguy Lefort (Univ. Montpellier, IMAG)
- Benjamin Charlier (Univ. Montpellier, IMAG)
- Camille Garcin (Univ. Montpellier, IMAG)
- Maximilien Servajean (Univ. Paul-Valéry-Montpellier, LIRMM, Univ. Montpellier)
- Alexis Joly (Inria, LIRMM, Univ. Montpellier)
and from
![]()
- Pierre Bonnet, Hervé Goëau (CIRAD, AMAP)
- Antoine Affouard, Jean-Christophe Lombardo, Titouan Lorieul, Mathias Chouet (Inria, LIRMM, Univ. Montpellier)
Pl@ntNet: ML for citizen science
![]()
A citizen science platform using machine learning to help people identify plants with their mobile phones


- Website: https://plantnet.org/
- Note: no mushroom identification!

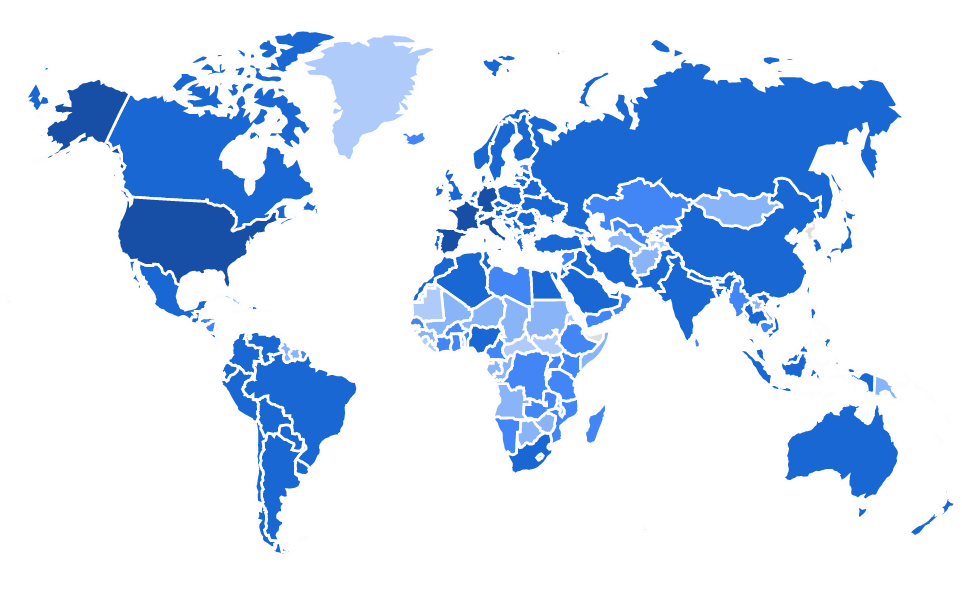
https://identify.plantnet.org/stats
- Start in 2011, now 25M+ users
- 200+ countries
- Up to 2M image uploaded/day
- 50K species
- 1B+ total images
- 10M+ labeled / validated

Pl@ntNet & Cooperative Learning






Note: I am mostly innocent; started working with the Pl@ntNet team in 2020
- Pl@ntNet-300K (Garcin et al. 2021): Creation and release of a large-scale dataset sharing the same property as Pl@ntNet; available for the community to improve learning systems

- Learning & crowd-sourced data (Lefort et al. 2024) and (Lefort et al. 2025): How to leverage multiple labels per image to improve the model? Need to assert quality: the workers, the images/labels, the model, etc.

- Top-K learning (Garcin et al. 2022): Driven by theory, introduce new loss to cope with Pl@ntNet constraints to output multiple labels (e.g., UX, Deep Learning framework, etc.)

Intra-class variability










Inter-class ambiguity










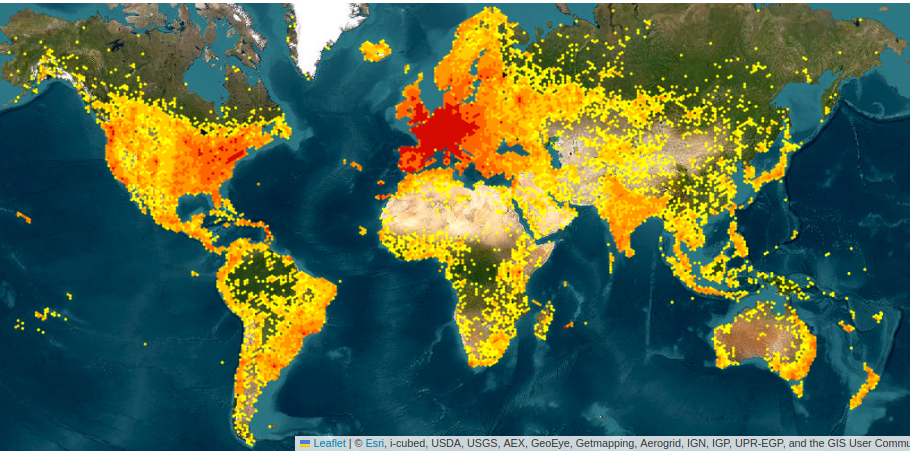
Top-5 most observed plant species in Pl@ntNet (13/04/2024):
25134 obs.  Echium vulgare L.
Echium vulgare L.
24720 obs.  Ranunculus ficaria L.
Ranunculus ficaria L.
24103 obs.  Prunus spinosa L.
Prunus spinosa L.
23288 obs.  Zea mays L.
Zea mays L.
23075 obs.  Alliaria petiolata
Alliaria petiolata
10753 obs.

Centaurea jacea
6 obs.

Cenchrus agrimonioides
8376 obs.

Magnolia grandiflora

413 obs.

Moehringia trinervia
Construction of Pl@ntNet-300K




- Earth: 300K+ species
- Pl@ntNet: 50K+ species
- Pl@ntNet-300K: 1K+ species
Note: long tail preserved by genera subsampling
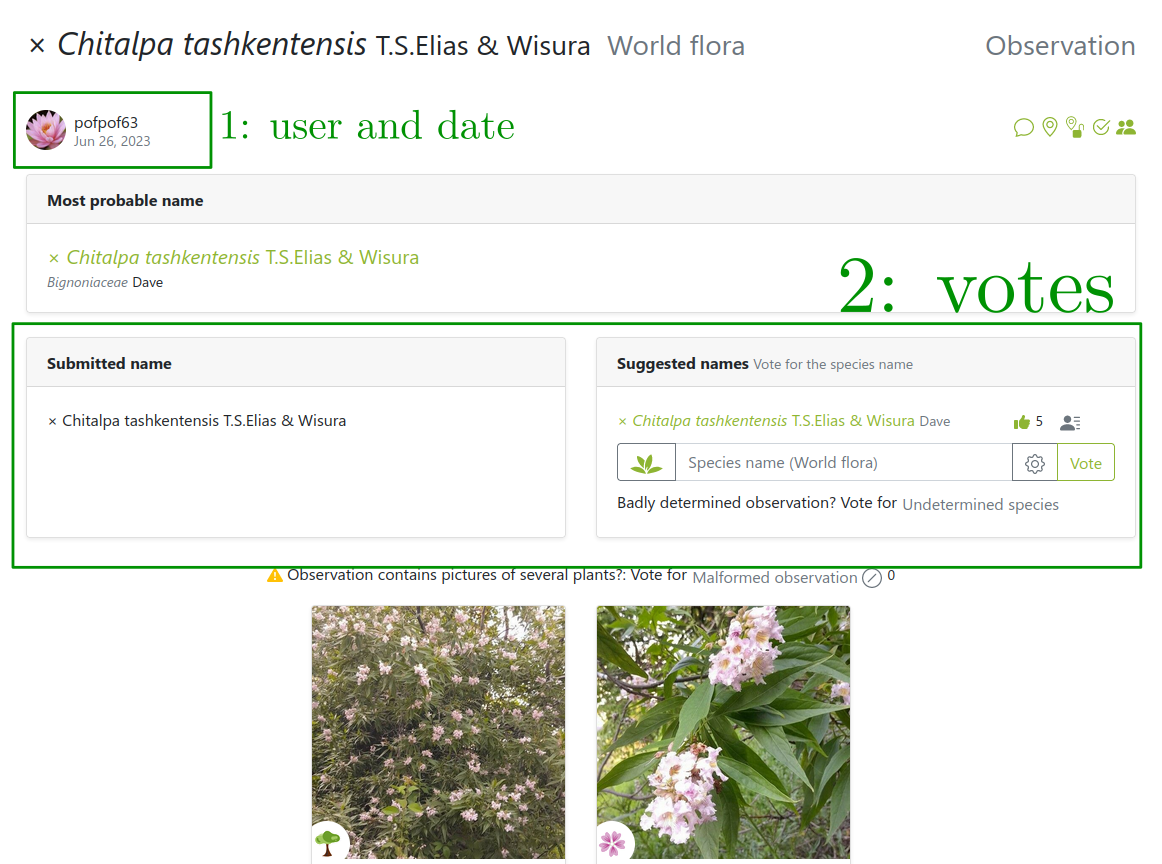
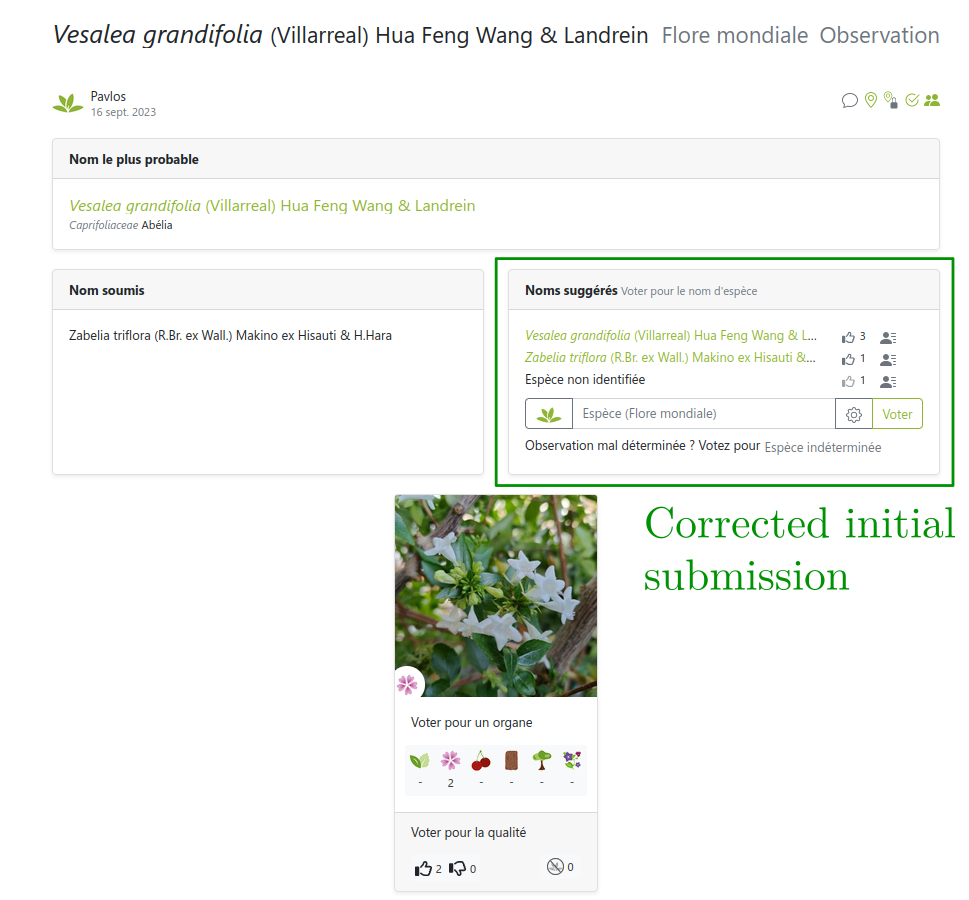
But sometimes users can’t be trusted
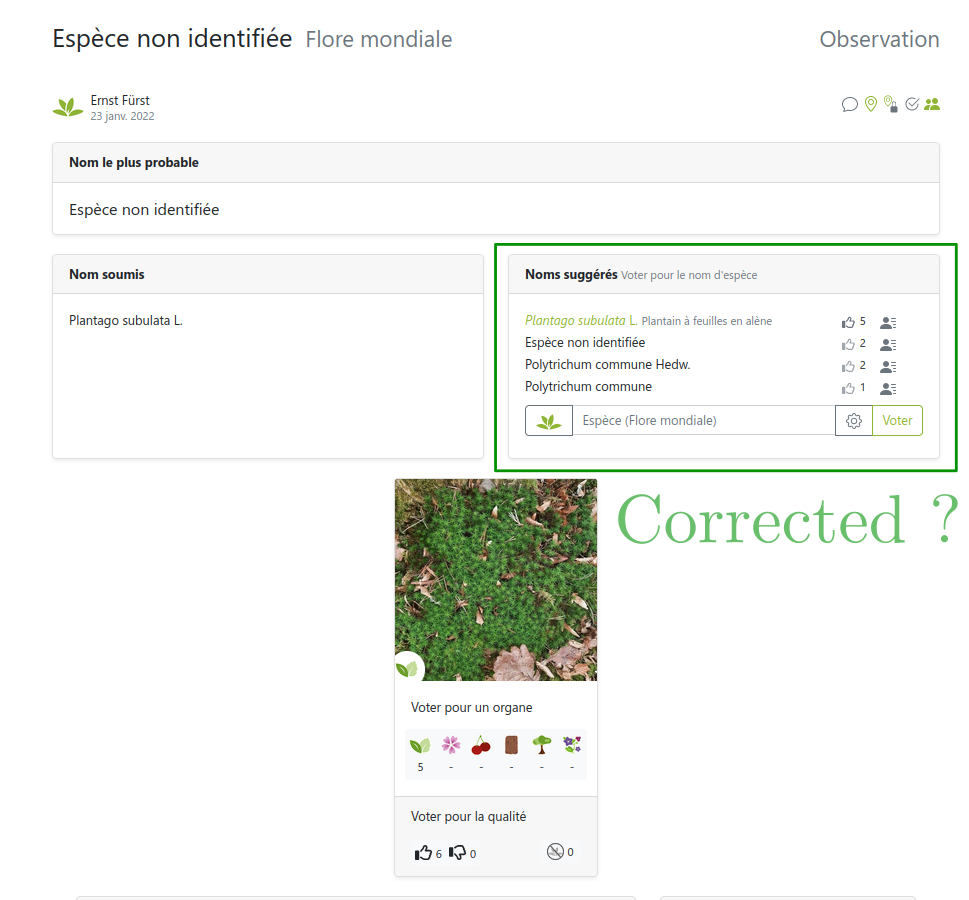
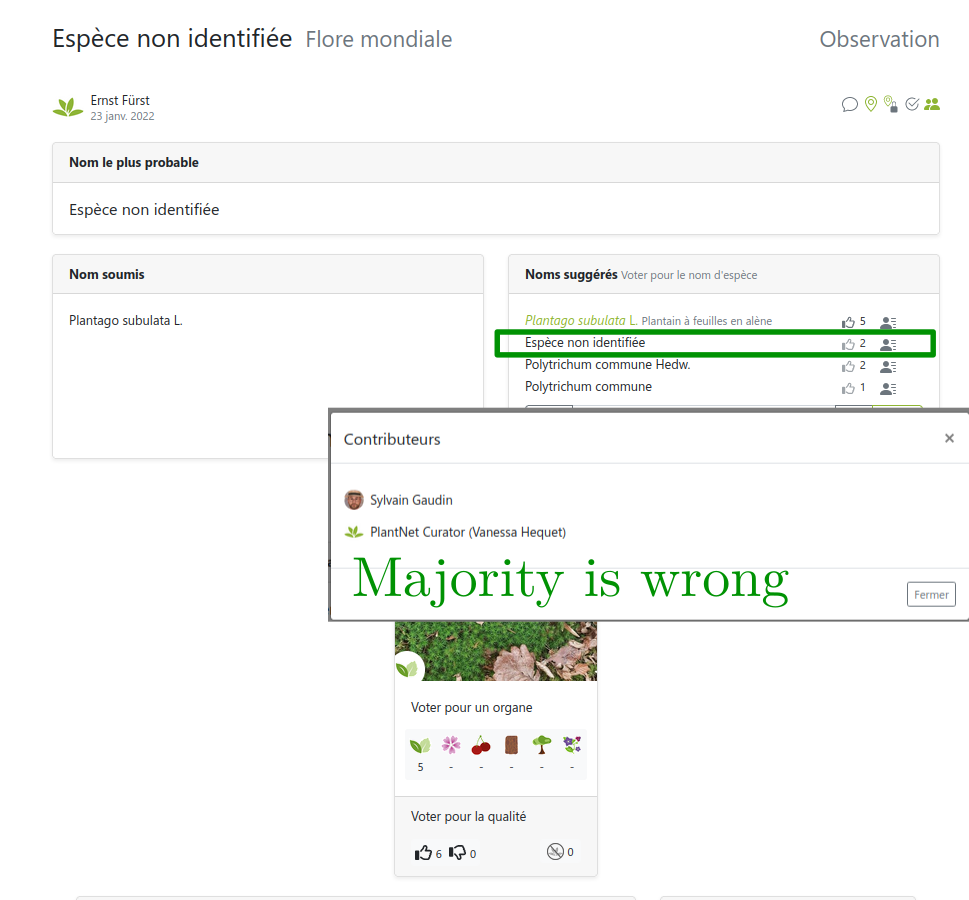
Link: https://identify.plantnet.org/weurope/observations/1012500059

Majority Vote (MV): intuitively
Naive idea: make users vote and take the most voted label for each image

Constraints: wide range of skills, different levels of expertise
Modeling aspect: add a user weight to balance votes

Assume given weights \((w_u)_{u\in\mathcal{U}}\) for now
Weighted Majority Vote (WMV): example

Pl@ntNet label aggregation (EM algorithm)
Weighting scheme: weight user vote by its number of identified species



Weights example
- \(n_{\mathrm{user}} = 6\)
- \(K=3\) : Rosa indica, Ficus elastica, Mentha arvensis
- \(\theta_{\text{conf}}=2\) and \(\theta_{\text{acc}}=0.7\)







Take into account 4 users out of 6
Take into account 4 users out of 6
Invalidated label: Adding User 5 reduces accuracy
Label switched: User 6 is an expert (even self-validating)
Choice of weight function
\[ f(n_u) = n_u^\alpha - n_u^\beta + \gamma \text{ with } \begin{cases} \alpha = 0.5 \\ \beta=0.2 \\ \gamma=\log(1.7)\simeq 0.74 \end{cases} \]

Test sets without ground truth
- Extract \(98\) experts: Tela Botanica + prior knowledge (P. Bonnet)

Pl@ntNet South Western European flora
Accuracy and number of classes kept

- Pl@ntNet aggregation performs better overall
- TwoThird is highly impacted by the reject threshold
- In ambiguous settings, strategies weighting users are better
Performance: Precision, recall and validity


- Pl@ntNet aggregation performs better overall
- TwoThird has good precision but bad recall
- We indeed remove some data but less than TwoThird
Aggregating labels: a new open source tool
peerannot: Python library to handle crowdsourced data



More on AI strategies
