{{
}}
Citizen science & machine learning for plant Identification: challenges from Pl@ntNet
Joseph Salmon
IMAG, Univ Montpellier, CNRS, Inria, Montpellier, France![]()
Consortium Pl@ntnet

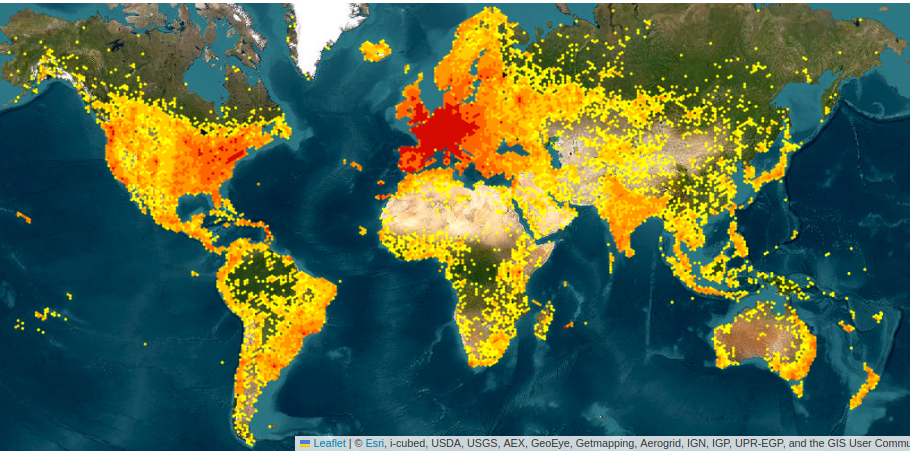
Pl@ntNet: ML for citizen science
![]()
A citizen science platform using machine learning to help people identify plants with their mobile phones







Alexis Joly
Primary investigator, INRIA
ResearchGate

Pierre Bonnet
Primary investigator, CIRAD
ResearchGate

Hervé Goëau
Researcher, CIRAD
ResearchGate

Antoine Affouard
Backend & Staff engineer, INRIA
LinkedIn

Jean-Christophe Lombardo
IA engineer, INRIA
LinkedIn

Mathias Chouet
Backend engineer, CIRAD
GitHub


Thomas Paillot
Front engineer, INRIA
LinkedIn

Rémi Palard
Geo & Fullstack engineer, CIRAD
LinkedIn

Vanessa Hequet
Botanist, IRD
LinkedIn

Murielle Simo-Droissart
Botanist, IRD
ResearchGate

Théo Simoes
Backend engineer, INRAE
LinkedIn

Jean-Marc Sadaillan
Project manager, INRAE
LinkedIn

Christophe Botella
Researcher, INRIA
ResearchGate

Joseph Salmon
Researcher, INRIA
Website

Benjamin Bourel
Researcher, INRIA
Website

Théo Larcher
PhD candidate, INRIA
LinkedIn

Giulio Martellucci
PhD candidate, INRIA
LinkedIn

Raphaël Benerradi
PhD candidate, INRIA
LinkedIn

Ilyass Moummad
Post-doc, INRIA
Personal website | Google Scholar






Note: I am mostly innocent, I started working with the Pl@ntNet team in 2020
- Collaborative effort, involving:
- machine learners
- ecologist
- engineers
- amateurs
- Open problems:
- theoretical
- methodological
- computational (due to the size of the problems)
- interfacing many disciplines

We need you: come and help us improve it!
- Pl@ntNet-300K (Garcin et al., 2021): Creation and release of a large-scale dataset sharing the same property (Long Tail!) as Pl@ntNet; available for the community to improve learning systems

- Prediction uncertainty quantification with long tail data (Ding et al., 2026) : providing prediction sets with statistical guarantees with Conformal Prediction

- Learning & crowd-sourced data (Lefort et al., 2024) and (Lefort et al., 2025): How to leverage multiple labels per image to improve the model? Need to assert quality: the workers, the images/labels, the model, etc.


_version_2.png)

Intra-class variability








Inter-class ambiguity


















Construction of Pl@ntNet-300K




- Earth: 400K+ species
- Pl@ntNet: 80K+ species
- Pl@ntNet-300K: 1K+ species
Note: long tail preserved by genera subsampling
Pl@ntNet300K: Long tail visualization

Tiffany Ding
UC Berkeley
within
![]()

Jean-Baptiste Fermanian
Inria
“Conformal Prediction for Long-Tailed Classification”
T. Ding, J.-B. Fermanian and J. Salmon
ICLR 2026
Pl@ntNet: set prediction (recommendation)

Elements to help guide the users
- provide a set of possible species/labels
- display similar images from proposed species
- give a score of confidence

Tanguy Lefort
Now at Seenovate
within
![]()

Benjamin Charlier
Inrae
“Cooperative learning of Pl@ntNet’s Artificial Intelligence algorithm:
how does it work and how can we improve it?”
T. Lefort et al.
Methods in Ecology and Evolution, 2025
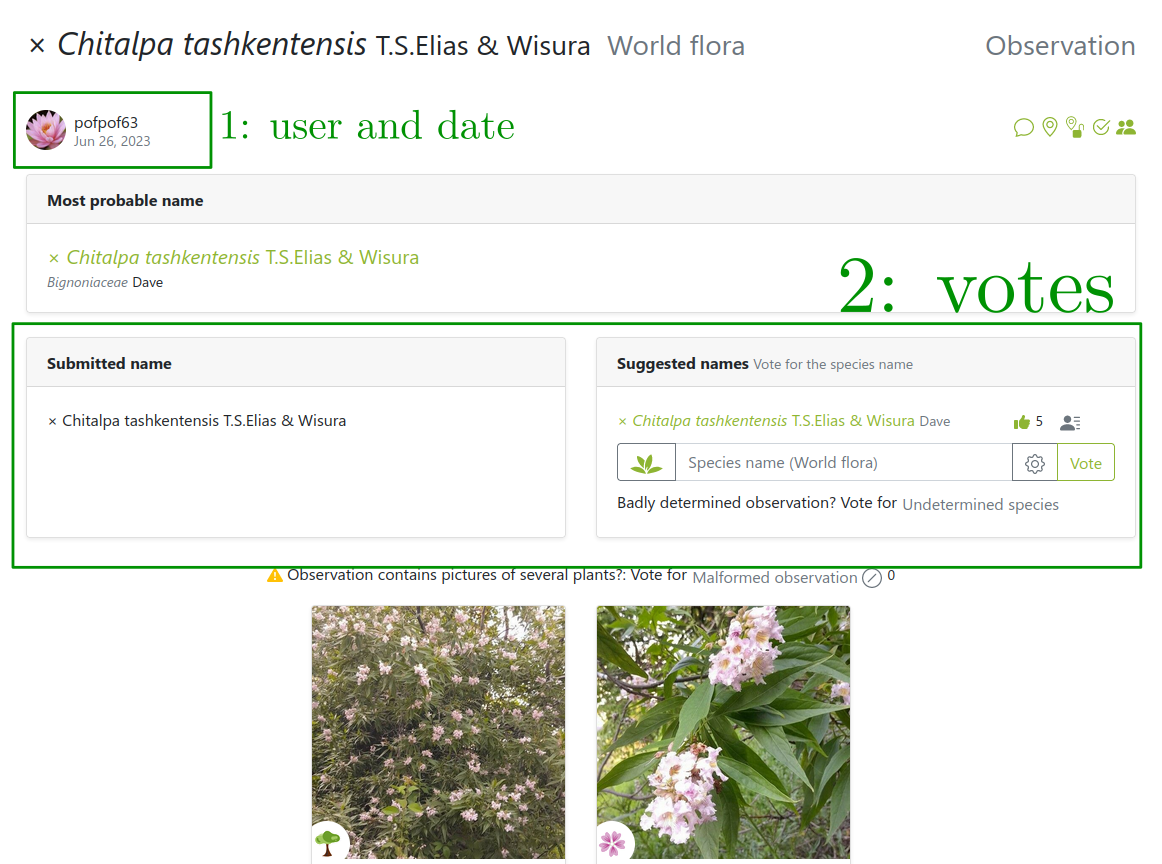
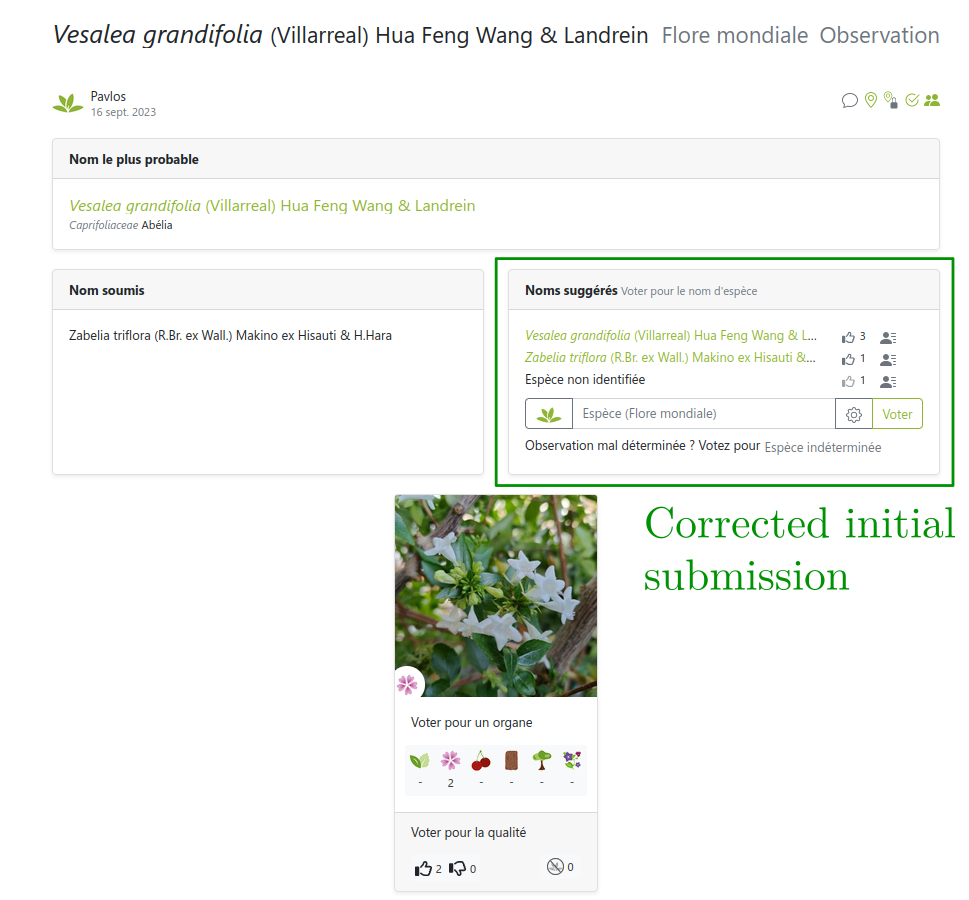
… sometimes can’t be trusted
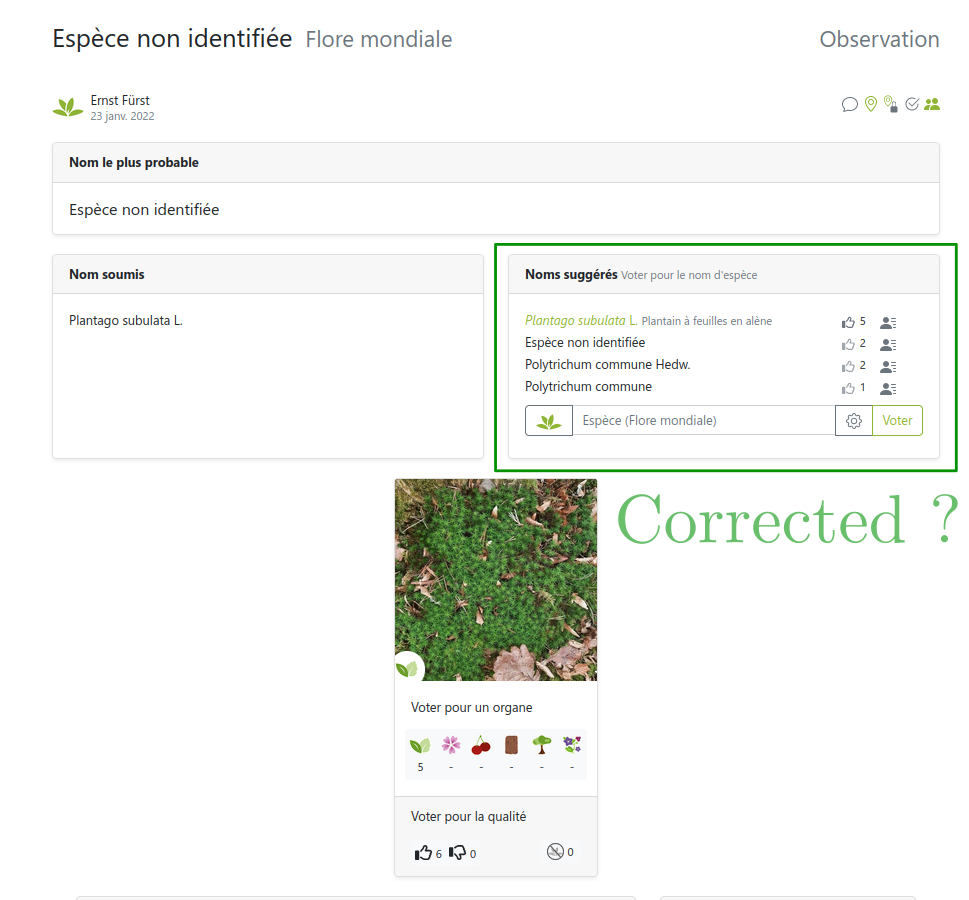
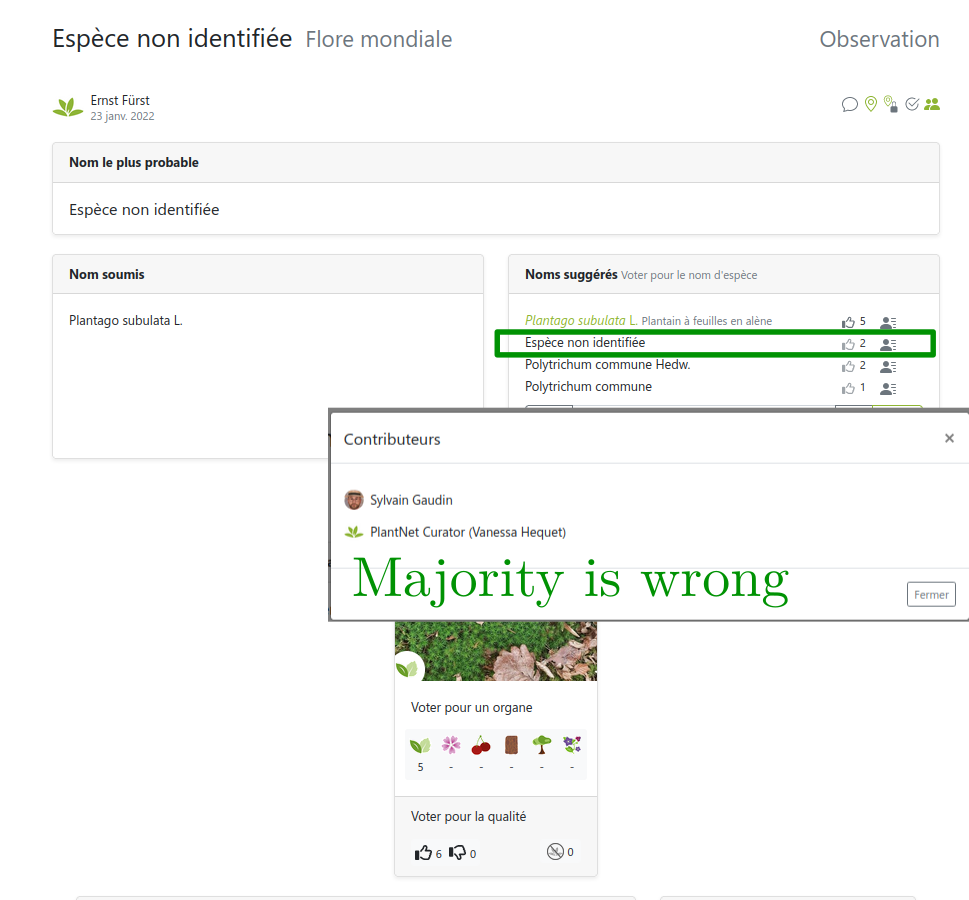
Link: https://identify.plantnet.org/weurope/observations/1012500059
Pl@ntNet label aggregation (EM algorithm)
Weighting scheme: weight user vote by its number of identified species



Take home message
- Challenges in citizen science: many and varied (need more attention)
- Crowdsourcing / Label uncertainty: helpful for data curation
- Improved data quality \(\implies\) improved learning performance
- Prediction: theory can guide the set to display

Dataset release:
- Pl@ntNet-300K: https://zenodo.org/record/5645731
- Pl@ntNet SWE flora: https://zenodo.org/records/10782465
Code release:
- Toolbox: https://peerannot.github.io/
- Some benchmarks: https://benchopt.github.io/
Future work
- Handling label hierarchy
- Human–computer interaction / performative learning / model collapse
- Improve robustness to adversarial users
- Leverage gamification for more quality labels theplantgame.com